Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries
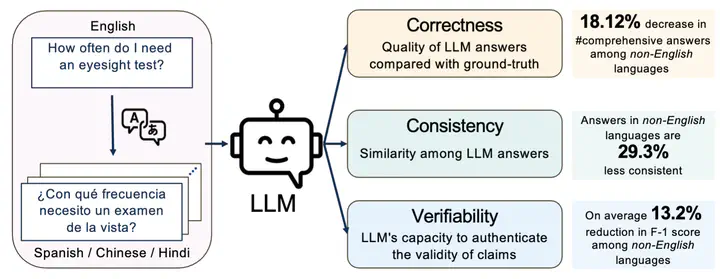 Image credit: Unsplash
Image credit: UnsplashAbstract
Large language models (LLMs) are transforming the ways the general public accesses and consumes information. Their influence is particularly pronounced in pivotal sectors like healthcare, where lay individuals are increasingly appropriating LLMs as conversational agents for everyday queries. While LLMs demonstrate impressive language understanding and generation proficiencies, concerns regarding their safety remain paramount in these high-stake domains. Moreover, the development of LLMs is disproportionately focused on English. It remains unclear how these LLMs perform in the context of non-English languages, a gap that is critical for ensuring equity in the real-world use of these systems.This paper provides a framework to investigate the effectiveness of LLMs as multi-lingual dialogue systems for healthcare queries. Our empirically-derived framework XlingEval focuses on three fundamental criteria for evaluating LLM responses to naturalistic human-authored health-related questions - correctness, consistency, and verifiability. Through extensive experiments on four major global languages, including English, Spanish, Chinese, and Hindi, spanning three expert-annotated large health Q&A datasets, and through an amalgamation of algorithmic and human-evaluation strategies, we found a pronounced disparity in LLM responses across these languages, indicating a need for enhanced cross-lingual capabilities. We further propose XlingHealth, a cross-lingual benchmark for examining the multilingual capabilities of LLMs in the healthcare context. Our findings underscore the pressing need to bolster the cross-lingual capacities of these models, and to provide an equitable information ecosystem accessible to all.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.
Yiqiao Jin
CS PhD Student
My research interests include large language models (LLMs) and multimodal learning, especially the evaluation, application, and fine-tuning of LLMs.