Semi-Offline Reinforcement Learning for Optimized Text Generation
 Model architecture and key components
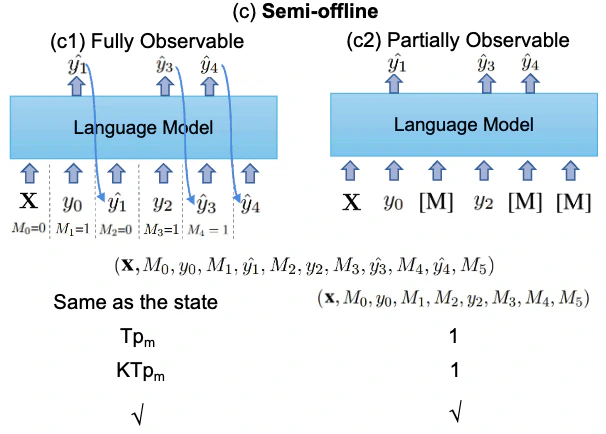
Model architecture and key componentsAbstract
Existing reinforcement learning (RL) mainly utilize online or offline settings. The online methods explore the environment with expensive time cost, and the offline methods efficiently obtain reward signals by sacrificing the exploration capability. We propose semi-offline RL, a novel paradigm that can smoothly transit from the offline setting to the online setting, balances the exploration capability and training cost, and provides a theoretical foundation for comparing different RL settings. Based on the semi-offline MDP formulation, we present the RL setting that is optimal in terms of optimization cost, asymptotic error, and overfitting error bound. Extensive experiments show that our semi-offline RL approach is effective in various text generation tasks and datasets, and yields comparable or usually better performance compared with the state-of-the-art methods.
Keywords
Reinforcement Learning, Text Generation, Language Models, Offline RL