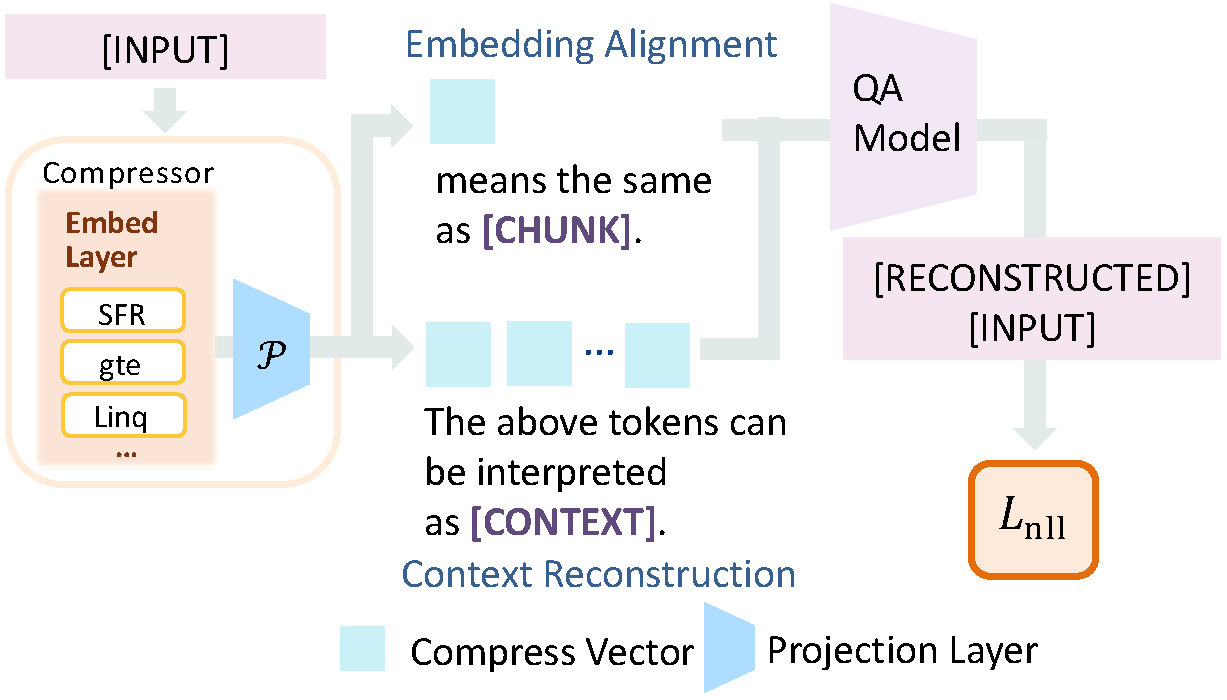
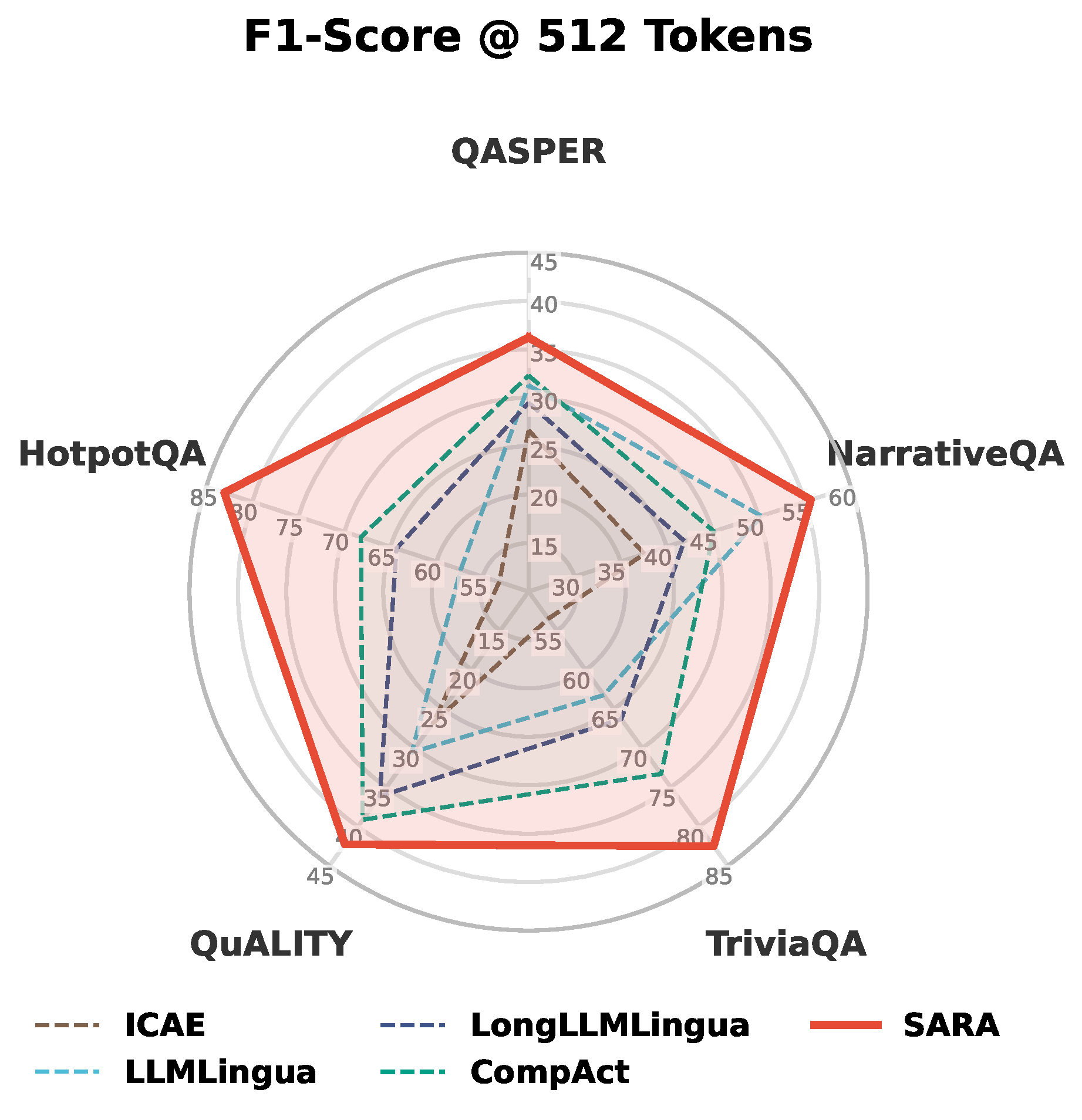
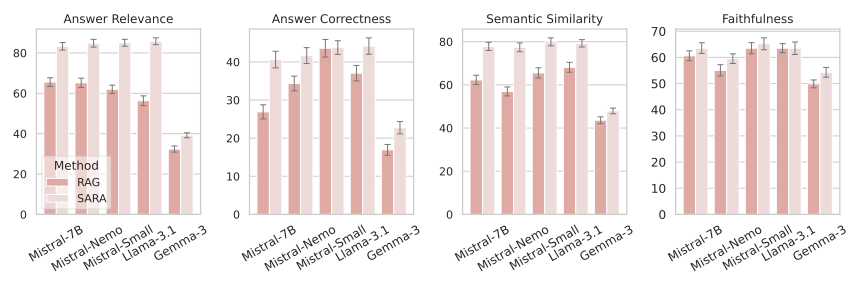
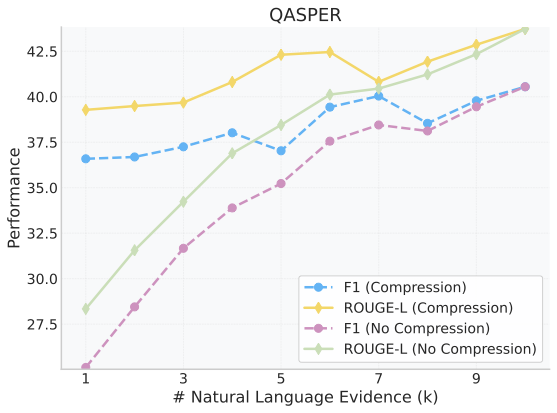
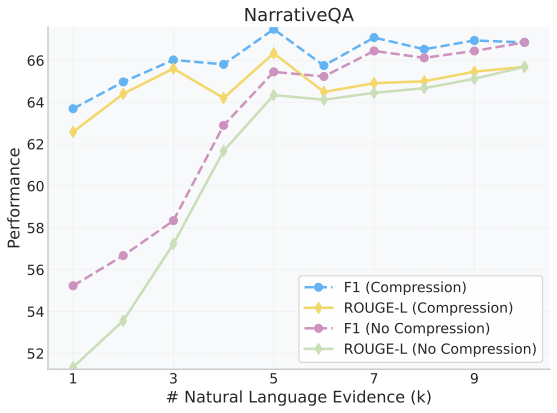
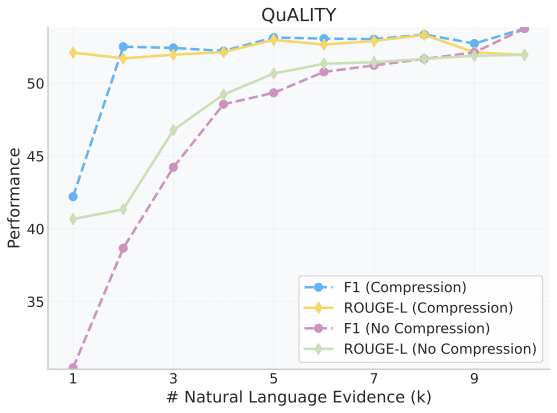
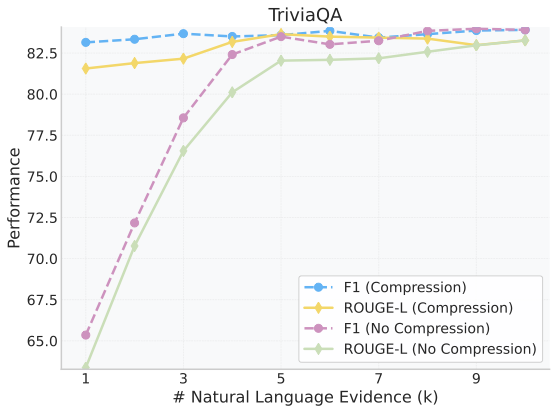
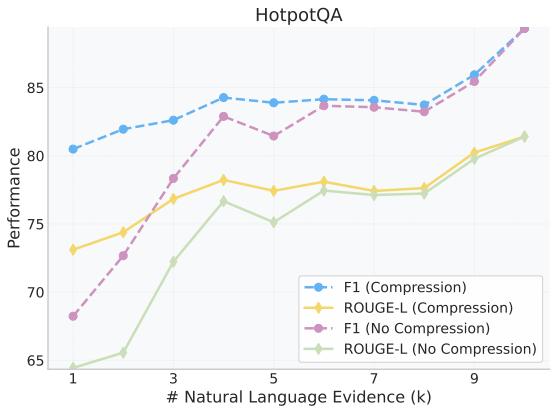
Retrieval-augmented generation (RAG) extends large language models (LLMs) with external knowledge, but it must balance limited effective context, redundant retrieved evidence, and the loss of fine-grained facts under aggressive compression. Pure compression-based approaches reduce input size but often discard fine-grained details essential for factual accuracy. We propose SARA, a hybrid RAG framework that targets answer quality under fixed token budgets by combining natural-language snippets with semantic compression vectors. SARA retains a small set of passages in text form to preserve entities and numerical values, compresses the remaining evidence into interpretable vectors for broader coverage, and uses those vectors for iterative evidence reranking. Across 9 datasets and 5 open-source LLMs spanning 3 model families (Mistral, Llama, and Gemma), SARA consistently improves answer relevance (+17.71), answer correctness (+13.72), and semantic similarity (+15.53), demonstrating the importance of integrating textual and compressed representations for robust, context-efficient RAG.